- Python (General)
- Python (LangChain)
- TypeScript
- REST API
To capture a RAG span, you can use the If you have document or chunk ids from the results, we recommend you can to capture them along with the id using Then you’ll be able to see the captured contexts that will also be used later on for evaluatios on LangWatch dashboard: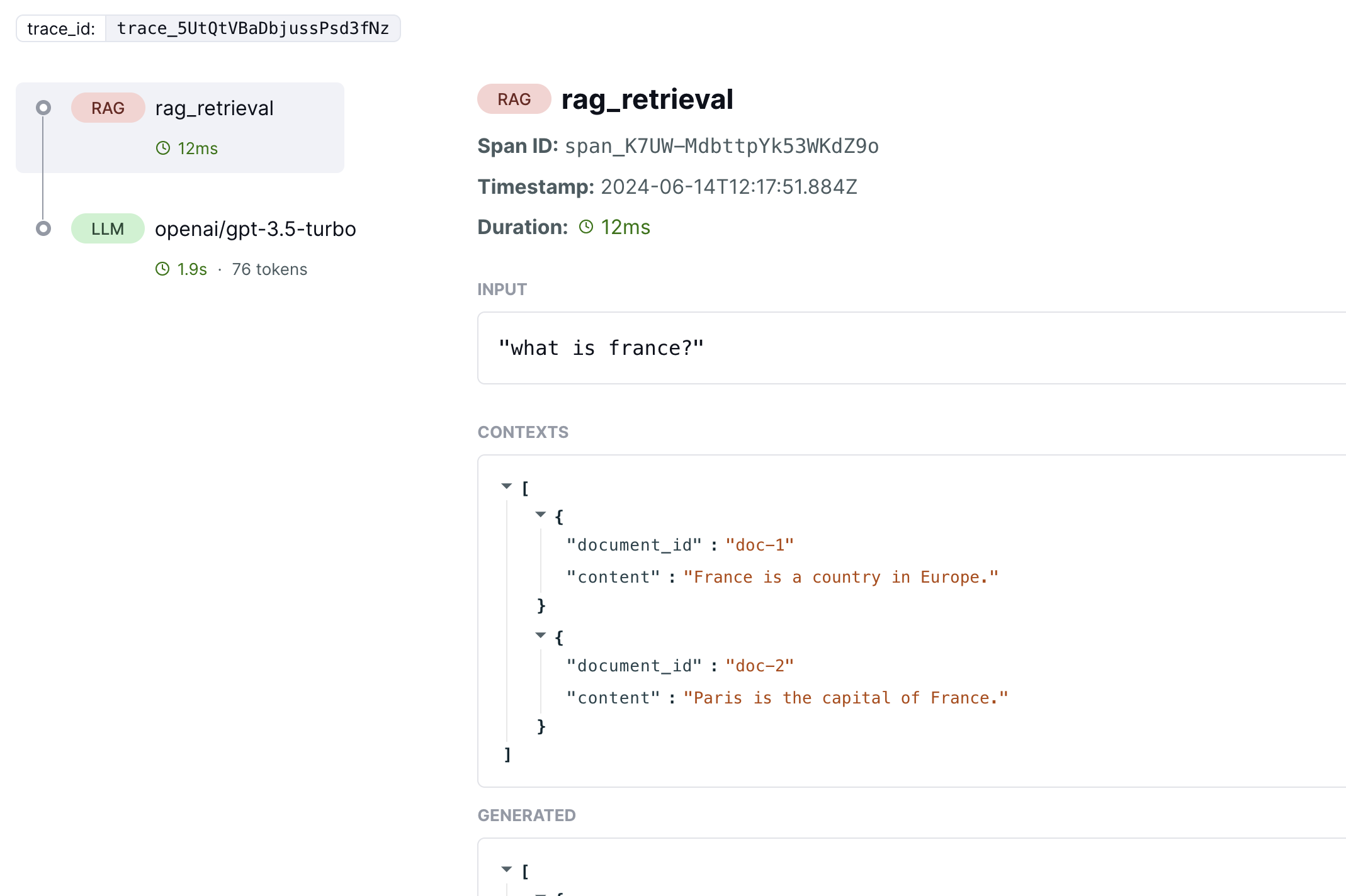
@langwatch.span(type="rag") decorator, along with a call to .update() to add the contexts to the span:RAGChunk, as this allows them to be grouped together and generate documents analytics on LangWatch dashboard: