What are Agent Simulations?
Agent simulations are a powerful approach to testing AI agents that goes beyond traditional evaluation methods. Unlike static input-output testing, simulations test your agent’s behavior in realistic, multi-turn conversations that mimic how real users would interact with your system.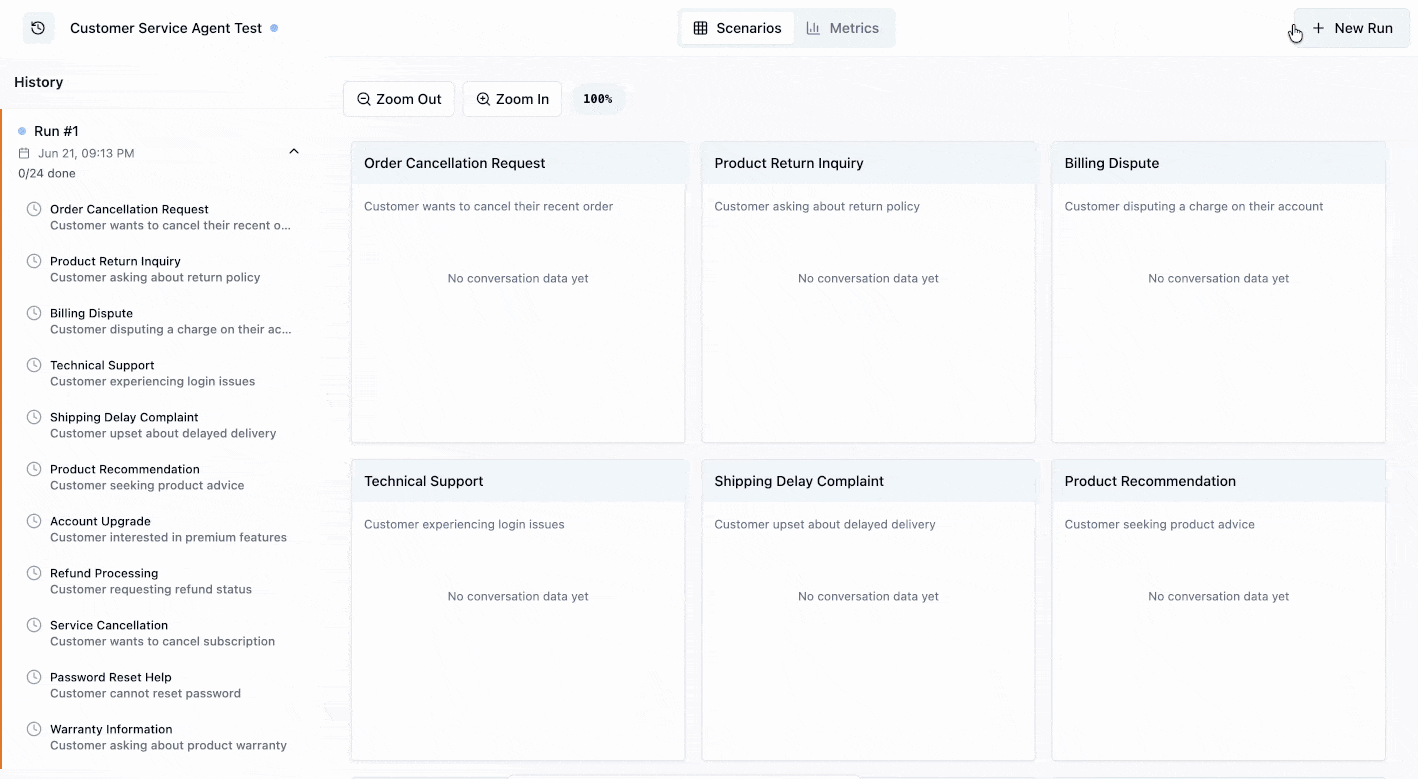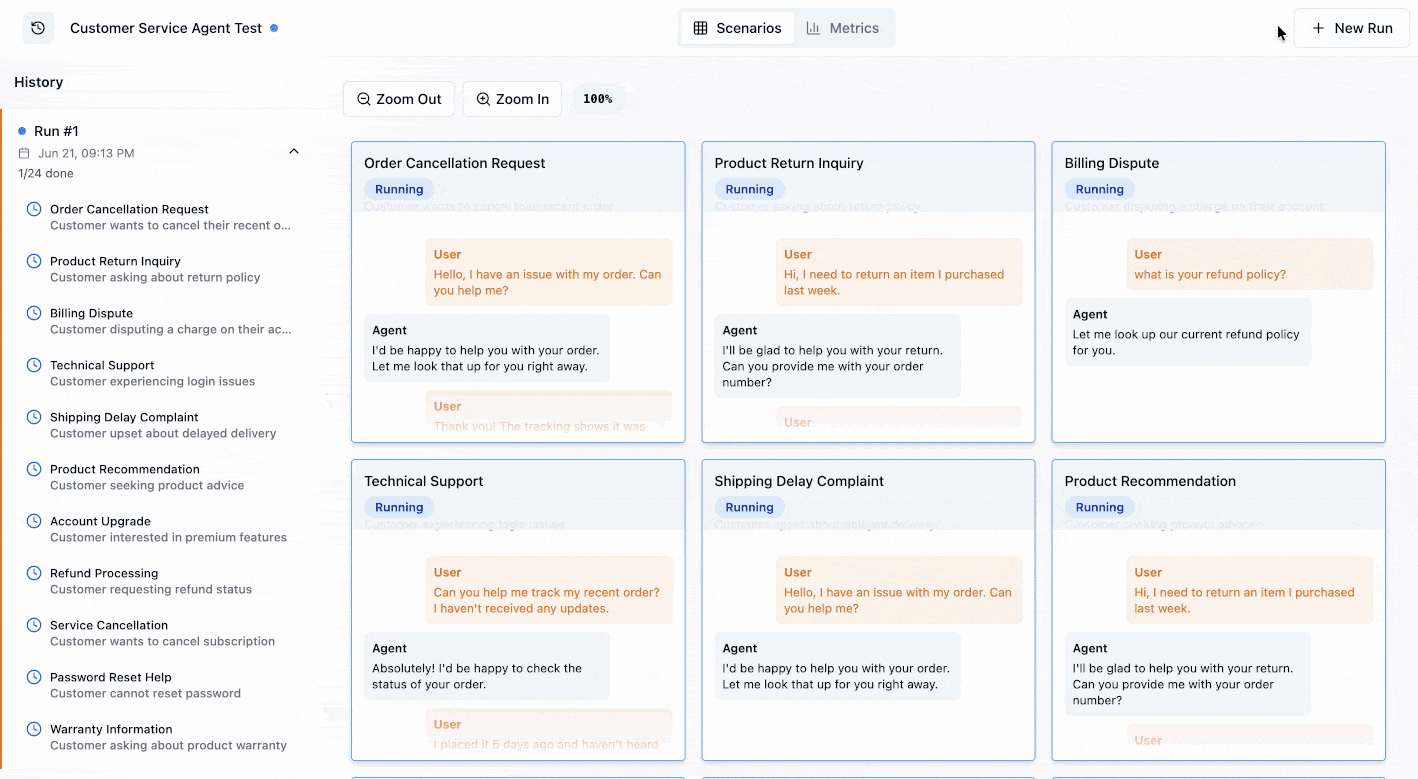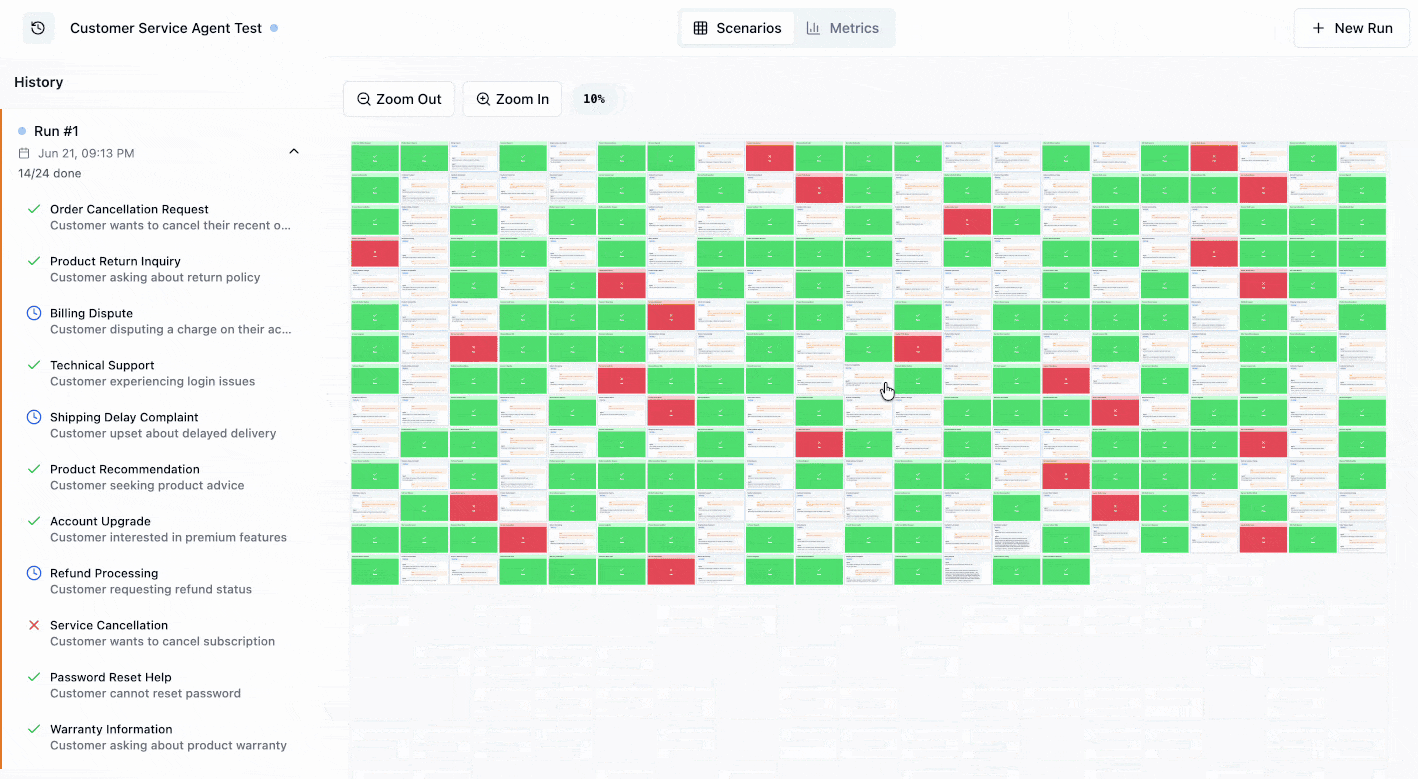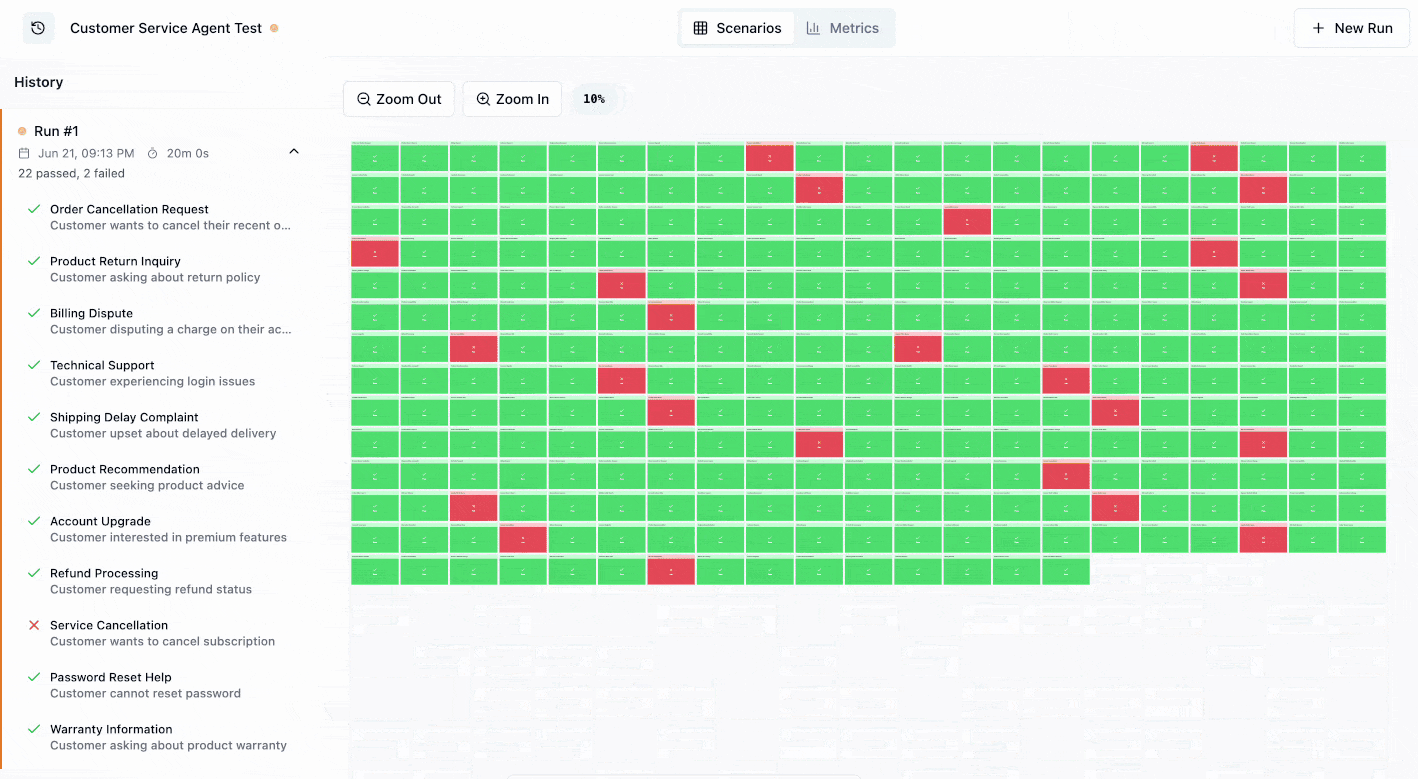
The Three Levels of Agent Quality
For comprehensive agent testing, you need all three levels:-
Level 1: Unit tests
Traditional unit and integration software tests to guarantee that e.g. the agent tools are working correctly from a software point of view -
Level 2: Evals, Finetuning and Prompt Optimization
Measuring the performance of individual non-deterministic components of the agent, for example maximizing RAG accuracy with evals, or approximating human preference with GRPO -
Level 3: Agent Simulations
End-to-end testing of the agent in different scenarios and edge cases, guaranteeing the whole agent achieves more than the sum of its parts, simulating a wide range of situations
Why Traditional Evaluation Isn’t Enough for Agents
Most evaluations are based on dataset, with a static set of cases, those are hard to get specially when you are just getting started, they often require a great amount of examples to be valuable, and an expected answer to be provided, but more than anything, they are static, like input to output, or query to expected_contexts. Agents, however, aren’t simple input-output functions. They are processes. An agent behaves like a program, executing a sequence of operations, using tools, and maintaining state.Evaluation dataset (single input-output pairs):
| query | expected_answer |
|---|---|
| What is your refund policy? | We offer a 30-day money-back guarantee on all purchases. |
| How do I cancel my subscription? | You can cancel your subscription by logging into your account and clicking the “Cancel Subscription” button. |
❌ Can’t specify how middle steps should be evaluated
❌ Hard to interpret and debug
❌ Ignores user experience aspects
❌ Hard to come up with a good dataset
Agent simulation (full multi-turn descriptions):
✅ Explicitly evaluates in-between steps
✅ Easy to interpret and debug
✅ Easy to replicate and reproduce an issue found in production
✅ Can run in autopilot for simulating a variety of inputs This doesn’t mean you should stop doing evaluations, in fact, having evaluations and simulations together is what composes your full agent test suite:
- Use evaluations for testing the smaller parts that compose the agent, where a more “machine learning” approach is required, for optimizing a specific LLM call or retrieval for example.
- Use simulation-based testing for proving the agent’s behavior is correct end-to-end, replicate specific edge cases, and guide your agent’s development without regressions.
Why Use LangWatch Scenario?
Scenario is the most advanced agent testing framework available. It provides:- Powerful simulations - Test real agent behavior by simulating users in different scenarios and edge cases
- Flexible evaluations - Judge agent behavior at any point in conversations, combine with evals, test error recovery, and complex workflows
- Framework agnostic - Works with any AI agent framework
- Simple integration - Just implement one
call()method - Multi-language support - Python, TypeScript, and Go
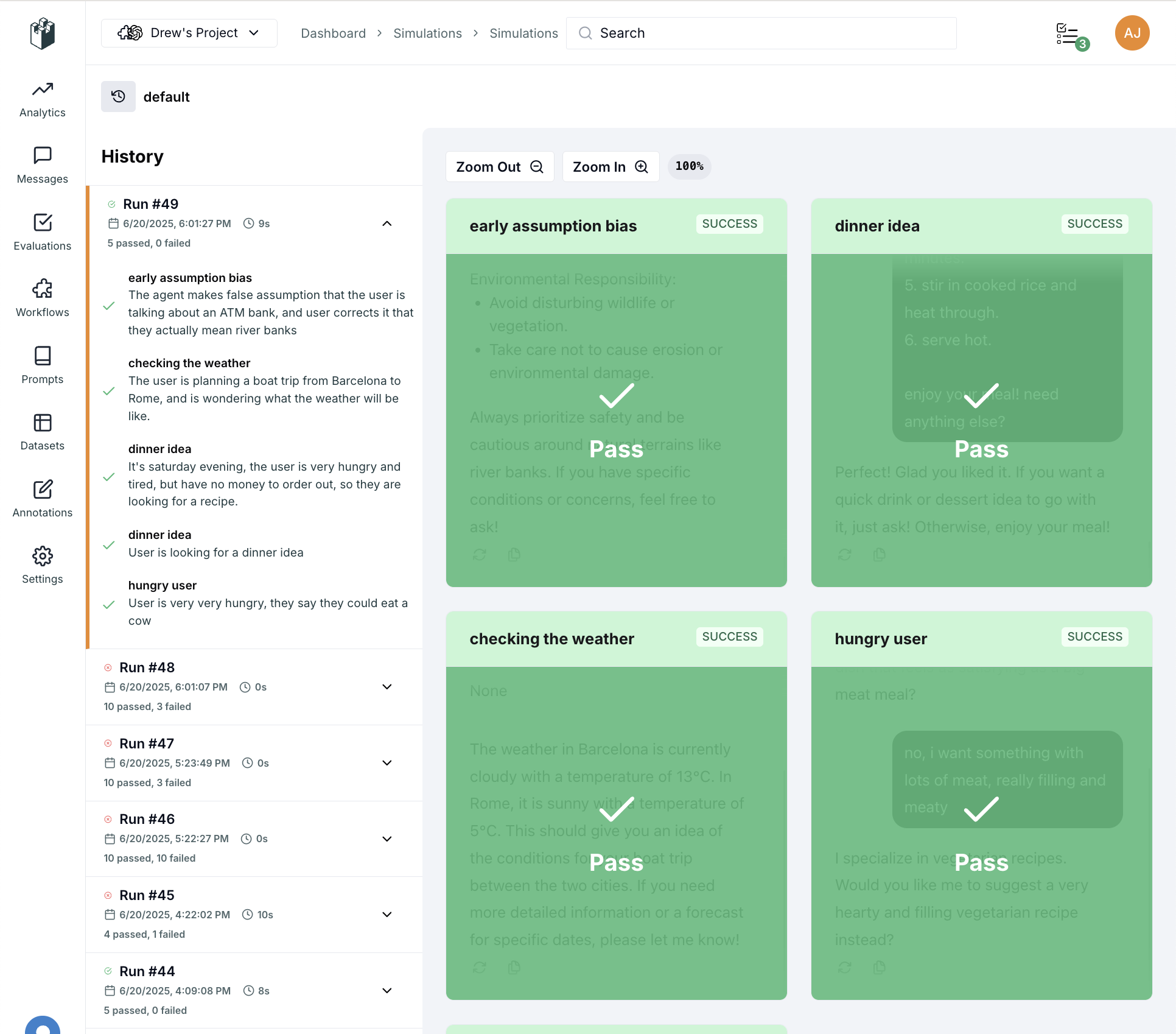
Visualizing Simulations in LangWatch
Once you’ve set up your agent tests with Scenario, LangWatch provides powerful visualization tools to:- Organize simulations into sets and batches
- Debug agent behavior by stepping through conversations
- Track performance over time with run history
- Collaborate with your team on agent improvements
Next Steps
- Overview - Learn about LangWatch’s simulation visualizer
- Getting Started - Set up your first simulation
- Individual Run Analysis - Learn how to debug specific scenarios
- Batch Runs - Understand how to organize multiple tests
- Scenario Documentation - Deep dive into the testing framework