Requirements
Before starting, ensure you have the following packages installed:Setup
Start by setting up LangWatch to monitor your RAG application:Retrieval Metrics
Before building our RAG system, let’s understand the key metrics we’ll use to evaluate retrieval performance: Precision measures how many of our retrieved items are actually relevant. If your system retrieves 10 documents but only 5 are relevant, that’s 50% precision. Recall measures how many of the total relevant items we managed to find. If there are 20 relevant documents in your database but you only retrieve 10 of them, that’s 50% recall. Mean Reciprocal Rank (MRR) measures how high the first relevant document appears in your results. If the first relevant document is at position 3, the MRR is 1/3.Generating Synthetic Data
In many domains - enterprise tools, legal, finance, internal docs - you don’t start with an evaluation dataset. You don’t have thousands of labeled questions or relevance scores. You barely have users. But you do have access to your own corpus. And with a bit of prompting, you can start generating useful data from it. If you already have a dataset, you can use it directly. If not, you can generate a synthetic dataset using LangWatch’sdata_simulator library. For retrieval evaluation, your dataset should contain queries and the expected document IDs that should be retrieved. In this example, I downloaded four research papers (GPT-1, GPT-2, GPT-3, GPT-4) and will use data_simulator to generate queries based on them.
Setting up a Vector Database
Let’s use a vector database to store our documents and retrieve them based on user queries. We’ll initialize two collections, one with small embeddings and one with large embeddings. This will help us test the performance of our RAG system with different embedding models.Parametrizing our Retrieval Pipeline
The key to running quick experiments is to parametrize the retrieval pipeline. This makes it easy to swap different retrieval methods as your RAG system evolves. In this example, we’ll compare a small and large embedding model based on recall and MRR. We’ll also vary the number of retrieved documents (k) to see how performance changes. First, we’ll define a function to retrieve documents.Visualizing the Results
Let’s visualize the results: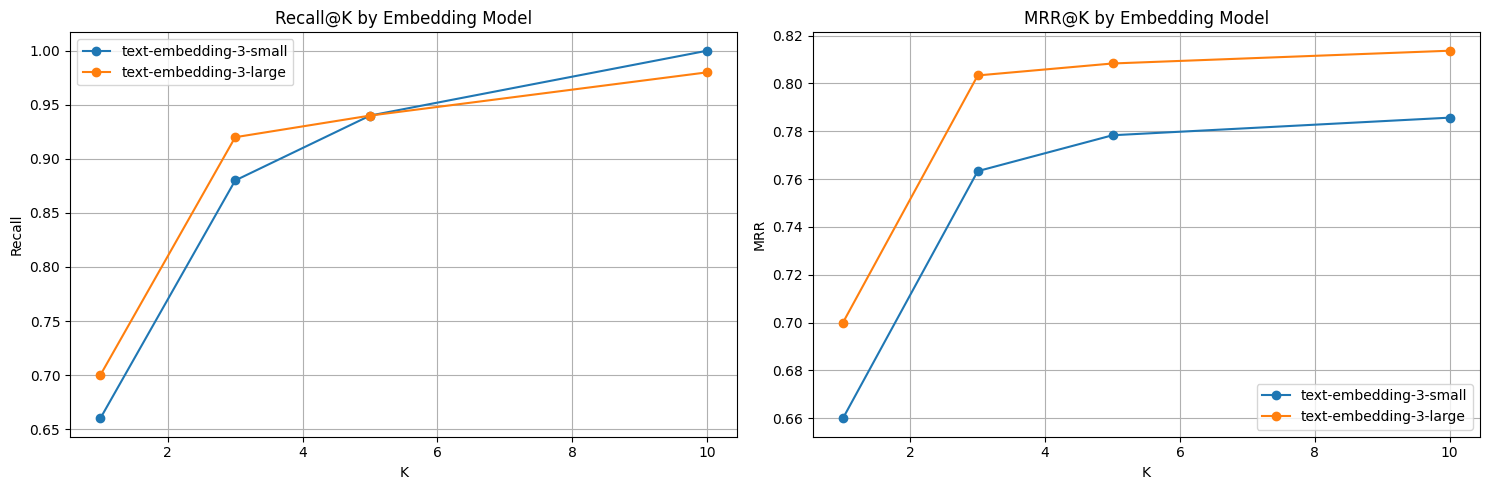
Comparison plot between Recall@K and MRR@K for different large/small embedding models
Conclusion
Based on our evaluation results, we can now make data-driven decisions about the RAG system. In this case, the smaller embedding model outperformed the larger one for our use case, which brings both performance and cost benefits. Since many factors influence RAG performance, it’s important to run more experiments — varying parameters like:- Document chunking strategies: Try different chunk sizes and overlap percentages
- Adding a reranker: Test if a separate reranking step improves precision
- Hybrid retrieval: Combine vector search with BM25 or other keyword-based methods
- Query expansion: Test if expanding queries with an LLM improves recall