DSPy RAG Module
As an example of RAG application we will use the sample app that is provided in the official documentation of DSPy library, you can read more by following this link - RAG tutorial. Firstly, lets access the dataset of wiki abstracts that will be used for example RAG optimization.api_key in the browser. Paste the API key into your code editor popup and press enter - now you are connected to LangWatch.
BootstrapFewShot is used and it will
bootstrap our prompt with the best demos from our dataset.
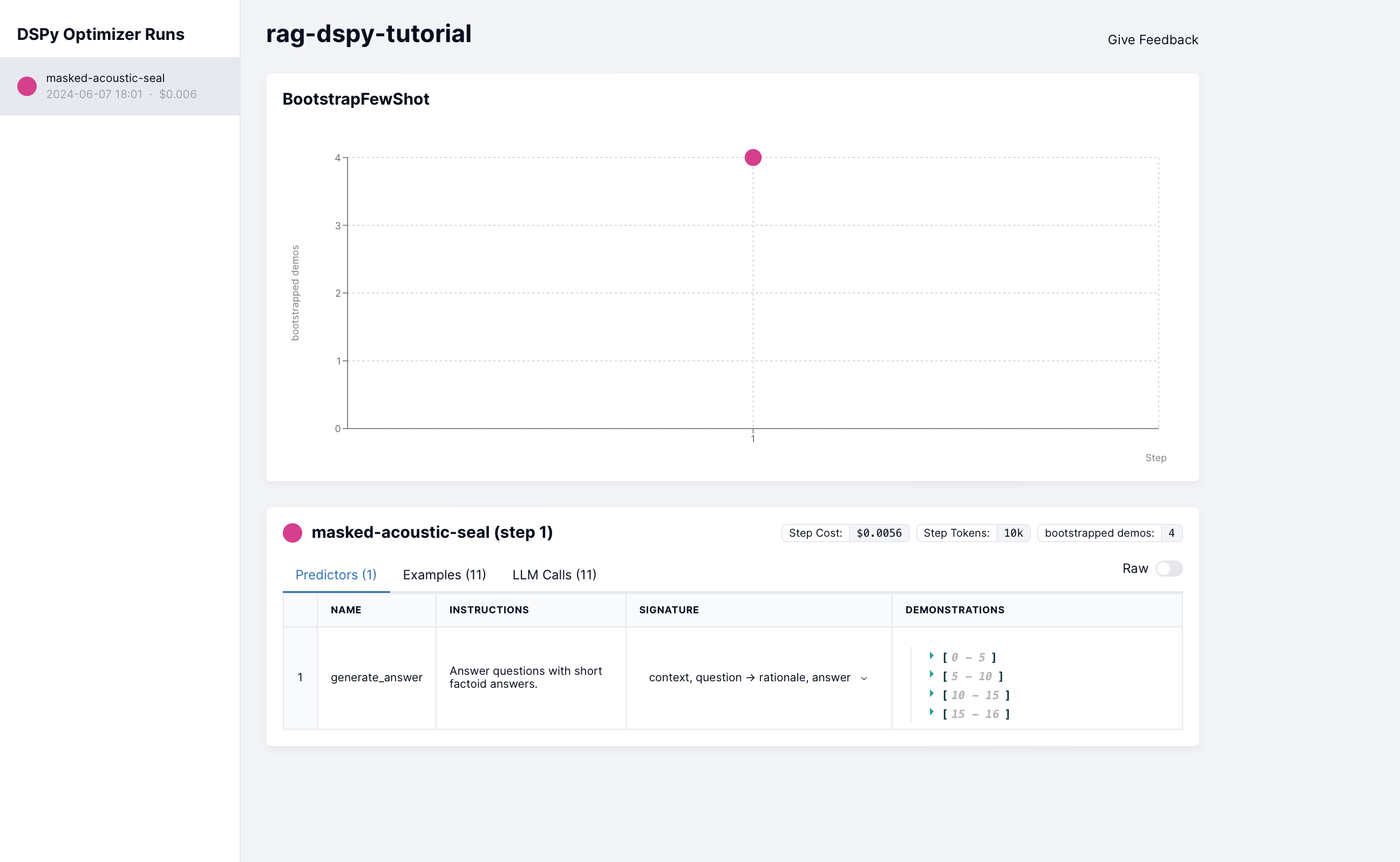
DSPy Experiment Dashboard
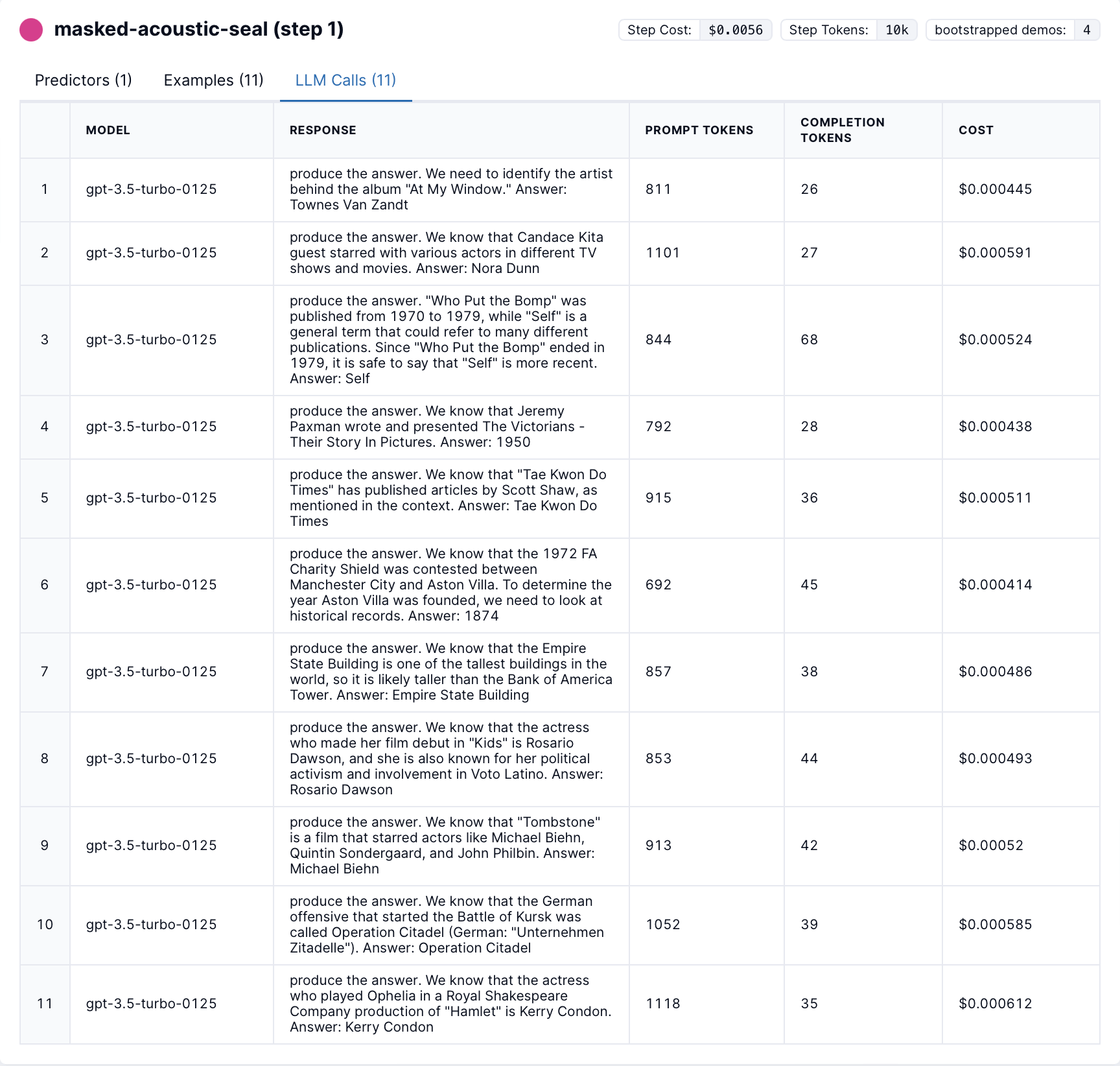
DSPy LLM calls
Open in Notebook
You can access and run the code yourself in Jupyter Notebook